Applies to: xSQL Data Compare v7.0.0 – v9.0.0
Business Need
A very common organization of the data infrastructure for big companies who operate in many countries and use some type of centralized system to manage their operations, is to have separate databases for each branch and one database that is operated by the headquarters that has the following data in it:
- A copy of all of the transactional data (sales, orders, etc.) from each branch.
- Lookup data like lists of products, services, categories, etc.
Both types of data need to be periodically synchronized between the central database and the branches’ databases. There are two directions for this synchronization.
Central -> Branches
This synchronizes the lookup data. For example, every time the company decides to add new products, services or even a new country where it operates, the logical way to go about this is to add the new data to the lookup tables in the central database and then synchronize the branches’ databases with this central database.
Branches -> Central
This synchronizes transactional data. This type of synchronization can be done at the end of every business day to transfer all the new or updated transactions from the branches to the central database which can then be used by the company’s HQ to build different types of reports.
Solution
xSQL Data Compare’s one-way synchronization. If the synchronization script is generated using the default options, it will make the database upon which it is executed, the same as the database with which it is compared. But in this case, that is not the desired result. Thankfully xSQL Data Compare offers the option to choose between synchronizing the left, right or different rows, or a combination of these options. This means that if you choose to synchronize only the right rows, rows that are in the right database but not in the left would be copied to the left, and rows that are in the left DB but not in the right would not be deleted.
To demonstrate this, below are the comparison results for the Products table of two Northwind databases (NORTHWND and NorthwindCopy). The Products table in the NORTHWND database does not have products with ID 8 to 14. The Products table in the NorthwindCopy database does not have products with ID 1 to 7. Also, the data for the product with id 20 is different in the NorthwindCopy database. A row is considered different if that row exists on both tables with the same primary key and at least one of the other fields is different. The goal here is to copy products with ID 8 to 14 and the changes in the product with ID 20 from the NorthwindCopy to NORTHWND. This means that xSQL Data Compare needs to generate a script for the left database (NORTHWND) where only the different and new rows from the right database will be synced. These rows will be left checked.
So, all the right rows will be checked:
And all the different rows:
To make sure that none of the rows that are in the left database’s table but not in the right is deleted, all the left rows will be unchecked:
Doing this will generate the following script (when Generate script for NORTHWND is clicked):
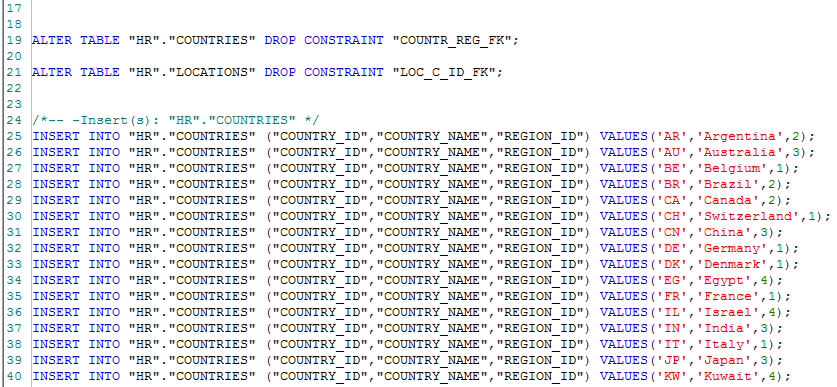
/*-- -Delete(s): [dbo].[Products] */
/*-- -Update(s): [dbo].[Products] */
SET IDENTITY_INSERT [dbo].[Products] ON;
UPDATE [dbo].[Products] SET [QuantityPerUnit]=N'35 gift boxes' WHERE [ProductID]=20
SET IDENTITY_INSERT [dbo].[Products] OFF;
/*-- -Insert(s): [dbo].[Products] */
SET IDENTITY_INSERT [dbo].[Products] ON;
INSERT INTO [dbo].[Products] ([ProductID],[ProductName],[SupplierID],[CategoryID],[QuantityPerUnit],[UnitPrice],[UnitsInStock],[UnitsOnOrder],[ReorderLevel],[Discontinued]) VALUES(8,N'Northwoods Cranberry Sauce',3,2,N'12 - 12 oz jars',40.00,6,0,0,0);
INSERT INTO [dbo].[Products] ([ProductID],[ProductName],[SupplierID],[CategoryID],[QuantityPerUnit],[UnitPrice],[UnitsInStock],[UnitsOnOrder],[ReorderLevel],[Discontinued]) VALUES(9,N'Mishi Kobe Niku',4,6,N'18 - 500 g pkgs.',97.00,29,0,0,1);
INSERT INTO [dbo].[Products] ([ProductID],[ProductName],[SupplierID],[CategoryID],[QuantityPerUnit],[UnitPrice],[UnitsInStock],[UnitsOnOrder],[ReorderLevel],[Discontinued]) VALUES(10,N'Ikura',4,8,N'12 - 200 ml jars',31.00,31,0,0,0);
INSERT INTO [dbo].[Products] ([ProductID],[ProductName],[SupplierID],[CategoryID],[QuantityPerUnit],[UnitPrice],[UnitsInStock],[UnitsOnOrder],[ReorderLevel],[Discontinued]) VALUES(11,N'Queso Cabrales',5,4,N'1 kg pkg.',21.00,22,30,30,0);
INSERT INTO [dbo].[Products] ([ProductID],[ProductName],[SupplierID],[CategoryID],[QuantityPerUnit],[UnitPrice],[UnitsInStock],[UnitsOnOrder],[ReorderLevel],[Discontinued]) VALUES(12,N'Queso Manchego La Pastora',5,4,N'10 - 500 g pkgs.',38.00,86,0,0,0);
INSERT INTO [dbo].[Products] ([ProductID],[ProductName],[SupplierID],[CategoryID],[QuantityPerUnit],[UnitPrice],[UnitsInStock],[UnitsOnOrder],[ReorderLevel],[Discontinued]) VALUES(13,N'Konbu',6,8,N'2 kg box',6.00,24,0,5,0);
INSERT INTO [dbo].[Products] ([ProductID],[ProductName],[SupplierID],[CategoryID],[QuantityPerUnit],[UnitPrice],[UnitsInStock],[UnitsOnOrder],[ReorderLevel],[Discontinued]) VALUES(14,N'Tofu',6,7,N'40 - 100 g pkgs.',23.25,35,0,0,0);
SET IDENTITY_INSERT [dbo].[Products] OFF;
As you can see, INSERT statements are generated for products with id 8-14. An UPDATE statement is also generated for Product with ID 20 and there are no DELETE statements.
Execute the script and there you have it, all the rows that are different and in NorthwindCopy but not in NORTHWIND are copied to the latter. To do the opposite, simply check all the left rows, uncheck the right and generate a script for NorthwindCopy.
One thing to note: In real life scenarios, to use this technique, it would be preferable to have all the Primary keys as ‘uniqueidentifiers’ to avoid primary key collision.
Automation
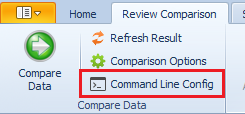
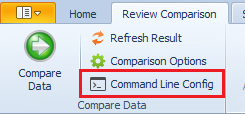
As always, xSQL Data Compare Command Line can be used to automate the entire process in order to perform this synchronization periodically. All you need to do is after you have specified the rows you want to sync is to generate the XML file that will be passed as an argument to xSQLDataCmd.exe. This can be done by clicking this button: