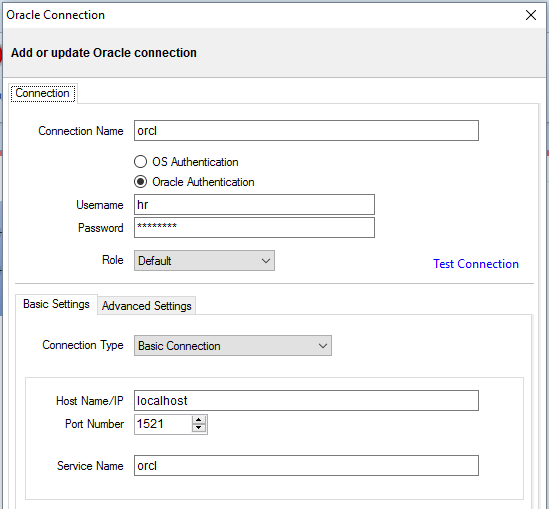
As a DBA doing data comparison and synchronization in databases, you would think that most of your tasks will be on databases that are exactly alike (schema-wise), because why bother placing the same data in two databases that are different right? Well, there are some exceptions in which these databases will have slight differences. For example, you might have two databases, one that stores the live data and one that stores the quality assurance data, in two different servers. Normally you assume that these databases will have the same tables and schemas with exactly the same names. However, there are cases (like mine), in which this is not the preferable option. I, for example, prefer to have some naming convention that would, by looking at the tables or schemas, clearly indicate in which database I’m in, just in case my brain freezes and I start making changes to the live database thinking it’s the quality assurance one. One such convention might be adding a prefix or suffix to the tables or schemas. How do you go about doing the synchronization process in these cases? Let’s look at an example with such synchronization done with
xSQL Data Compare.
As you can see, none of the objects in the 5 schemas in AdventureWorks2012 is listed
here. Thankfully, xSQL Data Compare allows for customization of object
mappings. This can be done by opening the mapping rules window, which looks
like this:

In the first tab you can specify how the
schemas are mapped. By default, xSQL Data Compare matches exact schema names.
The second option is to ignore the schema name, which will mean that tables
with the same name in different schemas will be mapped together. For databases
with multiple schemas this has a very high chance of throwing exceptions, but
if the databases being compared have only one schema and its name is different
in both databases ignoring the schema name is a very quick way to eliminate the
different names problem. Lastly, you can choose to manually specify the schema pairs
that will be mapped by selecting two schemas in the ‘Unmapped schemas’ section
and clicking on ‘Map selected schemas’. In this case I have manually chosen to map every schema in
AdventureWorks2012 with its equivalent in AdventureWorks2014. Here are the
schemas listed in the ‘Mapped Schemas’ section:

Before I show the results of this
configuration, let me explain what can be configured in the other tabs in the
‘Mapping Rules’ dialog. The second tab, ‘Name mapping rules’ allows you to specify
prefixes or suffixes to be ignored in table names. This isn’t covered in this
example but to quickly explain it, if you have a development database on the
right and a production database on the left whose table names have the ‘_dev’
and ‘_prod’ suffixes respectively, in this tab, you can tell xSQL Data Compare
to ignore these suffixes so that tables like ‘Employees_dev’ and ‘Employees_prod’
will be mapped together.
The third tab customizes how columns are
mapped according to their data types. By default, columns need to have the same
data type to be mapped together. This excludes character types which can be
either the UNICODE or the ASCII variant (e.g NVARCHAR and VARCHAR will still be
mapped together). However, you can specify the more lenient option of mapping
data types by compatibility because some data types are compatible with more
than one data type. For example, the DATETIME data type is compatible with
DATETIME (obviously), DATETIME2 and SMALLDATETIME. If this option is chosen and
a column has a DATETIME data type in one database and a SMALLDATETIME data type
in the other, they will still be mapped, whereas by default they would not have
been mapped.
Now, to show the results of the specified
schema mapping rules
As you can see, the tables in the schemas
(Production and QA_Production in this photo) are mapped together and will be
compared and synchronized.
This is all well and good, but what if
you want to map tables with entirely different names? If you have for example,
two databases that have a table with data about the products of a company, but
in one database this table is called ‘Products’ and in the other it is called
‘Articles’, ignoring prefixes or suffixes can’t really do the trick. In this
case you can either choose to "compare tables/views" option which allows you to manually map the tables/views, or you can use the command
line version. The GUI option is obvious and does not need much explaining, whereas the command line option is a bit more involved, In the xml configuration file that xSQL Data Compare Command Line utility can receive as an
argument you can specify a custom table mapping schema and then, specify the
table pairs, one by one. This will give you the freedom to map together any two
tables. Of course, they have to have the same columns in order to successfully
be compared and synchronized.
Here is the XML code to map together ‘Products’ and ‘Articles’ tables.
In conclusion, I hope to have provided a demo that will be of some help to all those DBAs or developers that have come across the scenarios mentioned in this article while comparing and synchronizing databases with tools such as xSQL Data Compare.