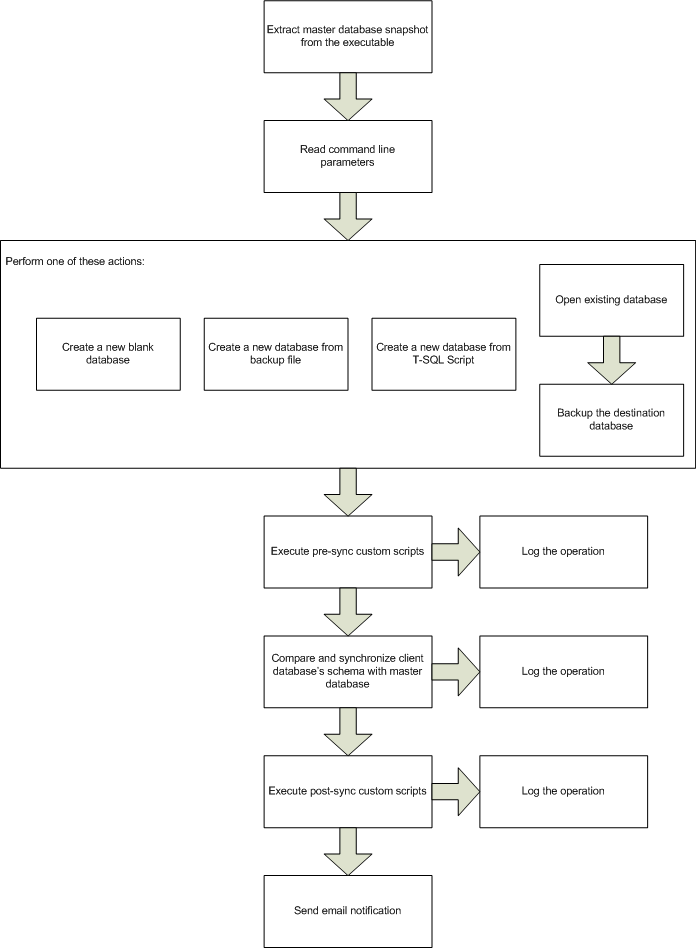
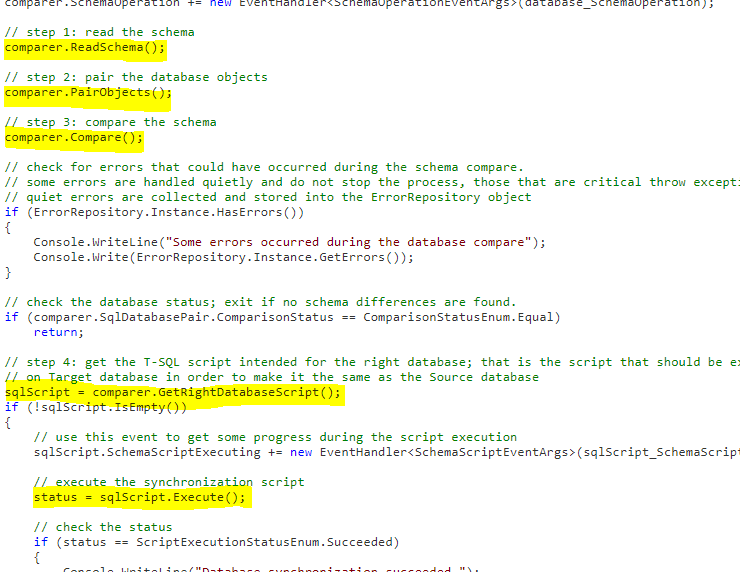
When you need to compare and synchronize data in two databases, in most cases, the schemas of the databases in question are the same, so Data Compare for SQL Server automatically pairs the tables and maps the columns based on names. However, there are cases when you might need to compare data in two tables with different names and different column names.
Data Compare for SQL Server provides the facility that allows you to map two tables with each other regardless of the table names, but the columns are automatically paired and there is no direct way to pair two columns with different names. Fortunately, there is a quick and easy workaround to this problem. Since xSQL Data Compare allows you to compare and synchronize SQL Server views as well you can do the following:

Download Data Compare for SQL Server now and try for yourself.
Data Compare for SQL Server provides the facility that allows you to map two tables with each other regardless of the table names, but the columns are automatically paired and there is no direct way to pair two columns with different names. Fortunately, there is a quick and easy workaround to this problem. Since xSQL Data Compare allows you to compare and synchronize SQL Server views as well you can do the following:
- Create two views (one for each table you wish to compare) with identical alias column names
- Compare and synchronize those two views instead – the columns will be mapped automatically since they have the same names but the updates during the synchronization will happen on the underlying columns which have different names.
A couple of limitations to be aware of:
- Since SQL Server does not support SET IDENTITY_INSERT ON|OFF on views, the insert statements might fail if one of the view’s underlying tables contains an identity column.
- Data Compare cannot synchronize views that contain large binary fields such as varbinary(max) and image, or views with large text field such as varchar(max), nvarchar(max), text and ntext.